
React Query Autosave: Avoid Data Loss | Patient Zero

EDITORS NOTE
Autosave is a standard user expectation, but implementing it correctly is surprisingly difficult. Naive implementations often lead to "race conditions" where out-of-order network requests overwrite user data. In this engineering guide, Irina Kudryavtseva shares a robust pattern for queuing mutations in React Query to guarantee data integrity.
Auto-saving is a common feature in many popular web applications like Gmail. Although it is very convenient for users it introduces certain challenges that developers and designers must address to ensure a seamless user experience.
For instance, when implementing an autosave feature, it's crucial to manage user expectations by providing clear feedback about when data is being saved and ensuring that there is no data loss during the save process. When it works, it can make your application feel natural and seamless, but if auto-save breaks (especially without notifying the user) it can destroy the user’s trust in your application.
Depending on the chosen technology, state management and app architecture, developers may face different issues with autosaving. But for simplicity of this discussion, let’s say we have a React app which uses react-query for state management, data fetching, caching, and background updates. We also have a number of controlled React components on a page, and every time a user interacts with this page, the same mutation request with a different payload representing the latest “state” that the user has entered or selected is made to update one database entity on the back end.
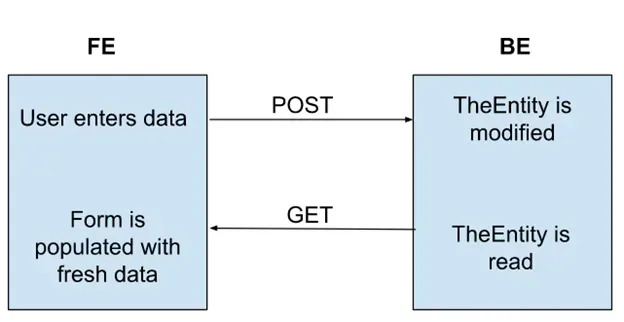
Impossible to lose any data in this simple setup, you say, but here we are.
As the user enters some precious information on the form, by checking checkboxes, selecting items from dropdowns or performing any other mutating activities, API requests get fired with new information, updating the same database entity. Due to the asynchronous nature of HTTP requests, we cannot guarantee when and in which order these API calls will arrive at the destination. If the requests arrived at the server out-of-order, the information entered by the user last would be overridden by the API call which arrived last, or if the API has been written with some kind of optimistic concurrency checking an error will be raised and some data changes will be lost. It’s also possible that the requests are received in the correct order, but the processing time of each request varies, and the net result is the same as the “out-of-order” scenario: the final state that is saved in the database is not the most recent data that the user entered.
Another risk is of the requests arriving at the same time and attempting to modify the same entity simultaneously. This is bad, no one wishes for a race condition in their system. In this case one of the mutations would never be completed due to an exception. All these errors will be transient and may be hard to reproduce.
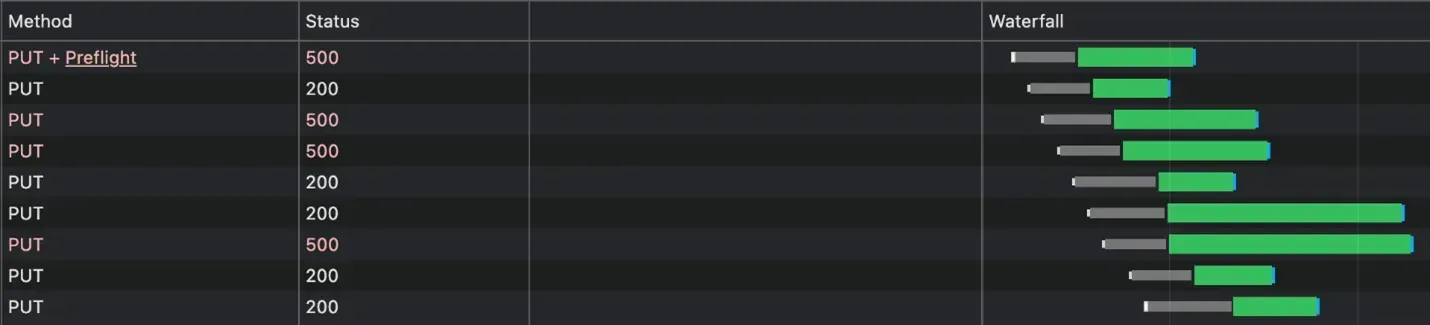
One way to address this issue would be to cancel the “in flight” mutation requests and issue a new one. React Query supports query cancellation, but not cancellation of mutations. This is for good architectural reasons - although simple APIs could process and handle the cancellation correctly it may not receive the cancellation until processing is complete. More complex APIs that can’t execute as a single atomic operation (and thus can’t be rolled back) couldn’t be cancelled properly, and the react-query developers wisely decided that supporting mutation cancellation would set an expectation that their front-end library could not deliver on.
To avoid data being written by out-of-order request processing and concurrency exceptions from race conditions, we decided to use queues to manage the order in which the requests are executed. This approach involves pushing requests to a queue and processing them one at a time, thereby eliminating the risk of race conditions. After some refinement, this solution moulded into the following reusable custom hook
useQueuedMutation:

This hook uses the same signature as useMutation from react-query for ease of use. Internally the useQueuedMutation hook adds a mutation to a queue when the queue method is called, performing the optimistic update straight away and also filtering out the mutations in the queue which did not start execution yet (isInFlight for them is false). When there are no in-flight mutations, the next mutation in line will start its execution. When the mutation is complete, it gets removed from the queue. This means the queue will at most have 1 pending mutation queued up. New incoming mutation calls will supersede queued ones, which will be evicted from the queue.
This approach guarantees the FIFO order of the request execution, eliminates exceptions due to concurrent entity updates and reduces load on the server by reducing the number of API requests. This makes our autosaving feature robust with no data loss in the process.

What happens if the user navigates away while a mutation is queued up? If the navigation is within the same React application the queued mutation will still be executed. If the user is closing the browser window or navigating to a URL outside of the current React application there is the potential for data loss. Handling these scenarios will be covered in a subsequent blog post.
Another approach for addressing these issues is debouncing the mutation requests. Although typically used to prevent time consuming tasks from being triggered too frequently, debouncing can also be used here to hopefully prevent these kinds of concurrency and out-of-order execution issues. I choose the word hopefully, because depending on the debouncing interval you choose they could still occur. A larger interval reduces the chance of the problem, but also reduces the “live”-ness of the user’s data and increases the amount of data that would be lost if the current state was unable to be saved. We also wanted to use React Query features like optimistic updates and using React Query controlled models as our component state, and switching to a debouncing strategy would have removed our ability to do this. Debouncing is still worth investigating if you don’t have these constraints.
Another approach which we intend to investigate further is using WebSockets for mutations in conjunction with react-query. WebSockets offer in-order, exactly-once delivery guarantees which HTTP does not. This would remove one of the reasons for requiring mutations to be queued, since they will always be processed in order. It would still be theoretically possible for issues if one mutation request was processed much more slowly than others. Queued updates also potentially reduce server load if mutations are slow, by triggering less of them.
Key Takeaways for Developers
- The "Out-of-Order" Trap: In asynchronous web apps, the last request sent isn't always the last one received. Without a queue, a slow "old" save can overwrite a fast "new" save, deleting user work.
- Queues > Debouncing: While debouncing reduces server load, it doesn't solve concurrency. Irina's
useQueuedMutationhook ensures strict FIFO (First-In-First-Out) execution, which is the only way to guarantee consistency. - Optimistic Updates: The solution preserves the ability to use Optimistic Updates (making the UI feel instant) while managing the background complexity safely.
Engineer Better Experiences
- Web Apps & Portals: See how we build robust, data-heavy enterprise portals. View Web Apps & Portals
- Software Development: Explore our React & Frontend engineering standards. View Software Development
- UX/UI Design: Learn how we design seamless interactions like Autosave. View UX/ UI Design
Build Rock-Solid Apps
Don't let race conditions destroy user trust. Partner with software engineers who understand distributed state management.
Share This Post
Get In Touch
Recent Posts



